
Background
In your dealings of developing firmware for embedded devices, you are bound to come across a design that needs you to design for reliability. I am not talking about hobby basic projects that can do without being robust, but rather projects and codebases that are robust-first, meaning they should never fail. These systems are classified as hard real-time systems, meaning that they are meant to be deterministic, whereby if you are reporting a sensor value, then that data from the sensor must be available at the expected time, come rain come shine.
However, you will find that once you have downloaded code into your embedded target, lets say to read the aforementioned sensor, you cannot really have full control over the system. By this I mean that there are some edge cases that you can never foresee. There is no perfect system basically. However, based on most projects I have done or come across, the best you can do to make a system deterministic is to make sure you have control over what happens if and when a fault occurs. The most common case is freezing, aka hanging.
Freezing in RTOS means that there is a blocked task somewhere that should be running but it is stuck in its loop or the like, waiting for some other event to occur for it to resume. This means that for as long as that task is frozen, there will be no operations from that specific task. This is a problem if your system is a hard real-time system. Based on my experience, this is an annoying bug to resolve if you do not have proper mitigation or control strategies that prevent freezing.
I personally dislike it when there is a bug in task that I cannot clearly log or don't know how to log, simply because I cannot see what’s causing the bug.
In this article I am going to show you a basic architecture design that I frequently use to detect and prevent task freezing. This is a method that I have used and it has worked for a fairly large number of tasks. In terms of scalability, the more the tasks you have, the more the need to track each and every task.
Excerpt
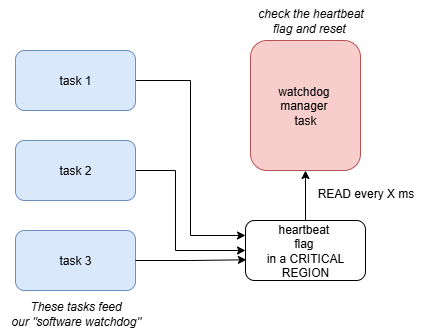
The basic idea behind this method is that each task keeps track of a status flag that is set at the end of its operation. Then there is a watchdog management task that collects all of these status flags and checks if they are set. This management task checks the flag for each task with a given frequency, so it means that after that period if a check is done and a task status flag is found to not be set, then that task is frozen and you implement control measures. See the block diagram below to further understand:
Implementation
I will just focus on the code related to software watchdog, other code for example creating tasks etc can be researched online easily. I am using an ESP32-DEVkit for this project.
Tasks creation
I create three tasks that simulate a real system collecting data with the code below:
/**
* @brief this task create other tasks
*/
void x_create_tasks() {
ESP_LOGI(debug_tag, "Creating tasks...");
/* task 1*/
xTaskCreate(
get_random_number_task, /* task code */
"get_random_number_task", /* task name */
1024, /* task stack size in words */
NULL, /* parameters to task */
2, /* priority */
NULL); /* task handle */
/* task 2 */
xTaskCreate(
read_time_task,
"read_time_task",
1024,
NULL,
2,
NULL);
/* task 3 */
xTaskCreate(
read_mpu_task,
"read_mpu_task",
1024,
NULL,
2,
NULL);
/* task 4 - watchdog task */
xTaskCreate(
watchdog_manager_task,
"watchdog_manager_task",
2048,
NULL,
1,
NULL);
}
Do not bother at parameters like stack size and task handles, as those will purely be at the discretion of the application writer.
Priority table
In terms of how the priorities should be allocated, it is generally known that the highest priority tasks are data collection tasks; or tasks that are responsible for reading sensors. In embedded all that matters is the data you get. So make sure enough CPU/core time goes to the sensor data collection tasks. In the above code you can see I have put the first three tasks to have a priority of 2.
The next priority goes to software management tasks such as the watchdog management task we are implementing.
Heartbeat
Now, the heart of this design is very simple. Each task has a bit that it maintains. I have created a bit mask that maps the bit position for each task. Here is the code for this:
/* heartbeat flag */
uint8_t heartbeat_flag = 0x00;
/* tasks heartbeat bit positions */
#define GET_RANDOM_NUMBER_TASK_FLAG (1 << 0)
#define READ_TIME_TASK_FLAG (1 << 1)
#define READ_MPU_TASK_FLAG (1 << 2)
As you can see, I have made the heartbeat flag a uint8_t, meaning that this flag can be used to monitor up to 8 individual tasks. 0,1 and 2 are bit positions that we will be checking.
Next is the code for the tasks themselves:
/**
* @brief task 1 to simulate reading an actual sensor into integer queue
*/
void get_random_number_task(void* pv_parameters) {
for(;;) {
//vTaskDelay(pdMS_TO_TICKS(1000));
/* crude method of mutual exclusion */
taskENTER_CRITICAL(&heartbeat_mux);
{
/* update heartbeat flag here */
heartbeat_flag |= GET_RANDOM_NUMBER_TASK_FLAG;
}
taskEXIT_CRITICAL(&heartbeat_mux);
vTaskDelay(pdMS_TO_TICKS(5));
}
}
/**
* @brief task 2 to simulate reading a uint32_t time
* this can be any sensor being read
*/
void read_time_task(void* pv_parameters) {
uint32_t time_32 = 123456789;
for(;;) {
//ESP_LOGI("read time task", "reading time");
taskENTER_CRITICAL(&heartbeat_mux);
{
/* update heartbeat flag here */
heartbeat_flag |= READ_TIME_TASK_FLAG;
}
taskEXIT_CRITICAL(&heartbeat_mux);
vTaskDelay(pdMS_TO_TICKS(2));
}
}
/**
* @brief simulate read into an IMU struct
*/
void read_mpu_task(void* pv_parameters) {
struct position_3d pos = {0};
for(;;) {
vTaskDelay(pdMS_TO_TICKS(250));
/* simulate reading x, y, z values here */
taskENTER_CRITICAL(&heartbeat_mux);
{
/* update heartbeat flag here */
heartbeat_flag |= READ_MPU_TASK_FLAG;
}
taskEXIT_CRITICAL(&heartbeat_mux);
vTaskDelay(pdMS_TO_TICKS(2));
}
}
Critical regions for shared variables
One of the big flaws in this design is that I am using a shared heartbeat variable that has to be written and accessed by multiple tasks. Good this is that FreeRTOS provides a provision for this. The basic idea is that when you are using a shared variable, you have to control the access to it. FreeRTOS provides three ways to do this:
- Semaphores
- Mutexes
- Critical regions
Semaphores and mutexes will be a discussion of another article. For this design I decided to use a crude way of access control, using CRITICAL REGIONS. Critical regions are basically a way of turning off and on global interrupts in FreeRTOS. How they work is that when you are just about to access a shared variable(critical region), you turn off interrupts so that no other task can access them, then you write/read your variable, finally you turn the interrupts back ON.
/**
* declare spinlock (mutex) variable first for use in critical section
* This is used specifically for esp32 because it has 2 cores, and track must be kept for which core has hold of the critical section.
*
* In other words we need to track the spinlock across the two cores
*/
portMUX_TYPE heartbeat_mux = portMUX_INITIALIZER_UNLOCKED;
You have to define a portMUX like above for ESP32. Then the code snippet below shows how to set the active bit on the watchdog shared variable:
/* crude method of mutual exclusion */
taskENTER_CRITICAL(&heartbeat_mux);
{
/* update heartbeat flag here */
heartbeat_flag |= GET_RANDOM_NUMBER_TASK_FLAG;
}
taskEXIT_CRITICAL(&heartbeat_mux);
Regular check of heartbeat flag
Let’s discuss the actual watchdog manager task. This task has only two functions, to check the heartbeat flag at regular intervals and to reset the heartbeat flag for the next cycle of tasks.
For this task to run at regular intervals, I use the vTaskDelayUntil API function:
void watchdog_manager_task(void* pv_parameters) {
TickType_t last_wake_time = xTaskGetTickCount();
const TickType_t watchdog_window = 100;
for(;;) {
/* wait for next cycle */
vTaskDelayUntil(&last_wake_time, watchdog_window);
// rest of the code.....
This sets the watchdog task to run deterministically every 100ms, which can be varied of course. Next, the core of this program is to check for task freezing, and since each task has a bit value that it sets, we simply AND the heartbeat flag with the task bit and check if its set. We do this for every task, every 100ms.
/* read the heartbeat flag and check for hanging task */
if(heartbeat_flag & (GET_RANDOM_NUMBER_TASK_FLAG)) {
/* get_random number task is running OK */
ESP_LOGI("watchdog manager", "get random number task OK");
} else {
ESP_LOGE("watchdog manager", "get random number task frozen, resetting...");
}
if(heartbeat_flag & (READ_TIME_TASK_FLAG)) {
/* read time task is running OK */
ESP_LOGI("watchdog manager", "read time task OK");
} else {
ESP_LOGE("watchdog manager", "read time task frozen, resetting");
}
if(heartbeat_flag & (READ_MPU_TASK_FLAG)) {
/* read mpu task is working OK */
ESP_LOGI("watchdog manager", "read MPU task OK");
} else {
ESP_LOGE("watchdog manager", "read MPU task frozen, resetting");
}
Resetting
After checking all the tasks, we need to reset the heartbeat flag, which is a critical region:
taskENTER_CRITICAL(&heartbeat_mux);
{
/* reset all bits and wait for the next watch window */
heartbeat_flag = 0x00;
}
taskEXIT_CRITICAL(&heartbeat_mux);
Tests
The following snippets show serial output for tests to check if this design works:
- All tasks running OK

- I introduce an intentional delay to read_mpu_task to simulate a blocking operation that causes the task to freeze. I use a vTaskDelay of 250ms and since the watch window is 100ms, this task will be considered frozen:
void read_mpu_task(void* pv_parameters) {
struct position_3d pos = {0};
for(;;) {
/* intentionally simulate freezing */
vTaskDelay(pdMS_TO_TICKS(250));
//…… rest of the code
Here is the serial output for this:

Then what?
One thing you realize is that once we discover that a task is frozen then what? How do we un-freeeze it? There are several strategies, which would require an article of there own.
But the strategy depends on the system and the application writer. Here is a list of some of the strategies that can be used:
- Delete the task and recreate it - this is called targeted resetting
- Reset the whole system - bad design because you are introducing collateral damage to tasks that are running OK
- Do a power cycle - For critical systems, sometimes it reaches a point where you have to power cycle. You could have a function that enables and reenables an LDO for example.
Code
Here is the link to full code:
https://github.com/bytecod3/freertos-esp32/tree/main/software_watchdog_monitoring
Thanks. Am out!